Jamba - Mamba & Transformers & MoE
Motivation§
The domain of ML has made some remarkable progress in the last 6 years. A lot of credit goes to a capable architecture - the Transformer. Transformer based models are very capable but are not very efficient in memory or compute. Recently another architecture has shown real promise in terms of efficiency and memory - Mamba. But they lag behind in performance.
One might ask, is there some way the two can be combined (if they can be combined), to create a
novel architecture such that one guards against the other's shortcomings and together the combined
model can be equally as capable as transformer or better. The Jamba paper explores just that.
Background§
Let's compare Mamba and Transformer head to head.
| Category | Transformer | Mamba | Comment |
|---|---|---|---|
| Memory footprint | High | Low | Lower is better |
| Compute requirement | High | Low | Lower is better |
| Trained efficiently | Yes | Yes | - |
| Performance | Best | Lower than transformer | - |
| Supports very long context | No | Yes | Longer the context the better |
| In context learning | Yes | No | - |
Results§
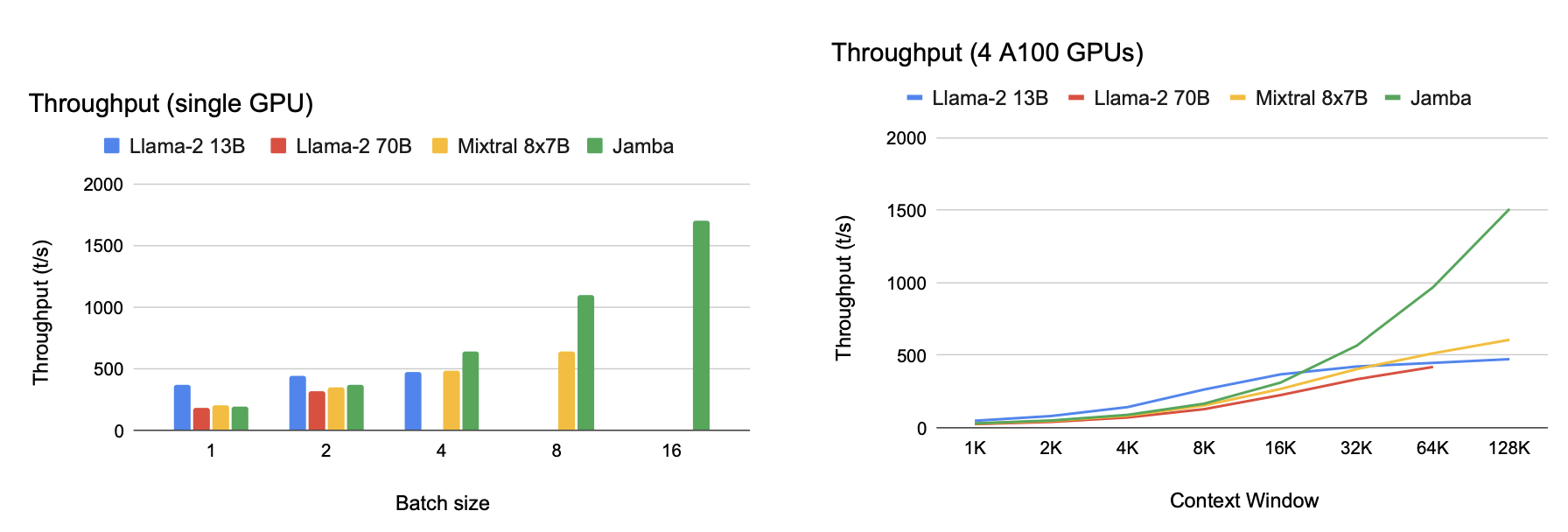
Throughput§
Impressive throughput at high context lengths. The large llama model does not even get to this
context length. It bears mentioning that the released Jamba model supports a context length of 256K
and it has been tested for up to 1M tokens.
Memory Footprint§

Jamba can work with 1/8th the K/V cache size compared a pure Transformer based model.

Performance§
Jamba is descent in reasoning - wins on 3 out of the 5 categories. But on the two that it looses, it
looses by a wide margin to the winner. On the ones it wins, it wins by a small margin. It does quite
poorly on comprehension and aggregate categories.

It does well on Needle in a haystack problems.

Architecture§
12 B active parameters and 52 B total available parameters. Training runs up to 250 B tokens.

The architecture uses 4 such blocks.
Other findings§
- Pure Mamba struggles with in-context learning.
- Jamba does not need positional embeddings.
- The ratio of attention to Mamba layers may be 1:3 or 1:7 with no performance difference. This was done on a 1.3B parameter model trained with 250B tokens.
- The paper claims that the Jamba
Thoughts§
The research shows that Transformer and Mamba can be combined in meaningful ways to create efficient models in terms of training compute and memory but Transformers are still the king when it comes to state of the art in performance. Whether they will continue to be the crown less kings - remains to be seen. Mamba is seeing some love from the community and time will tell if some hybrid architecture can end the reign of the transformers.
Reference§
- https://arxiv.org/pdf/2403.19887.pdf